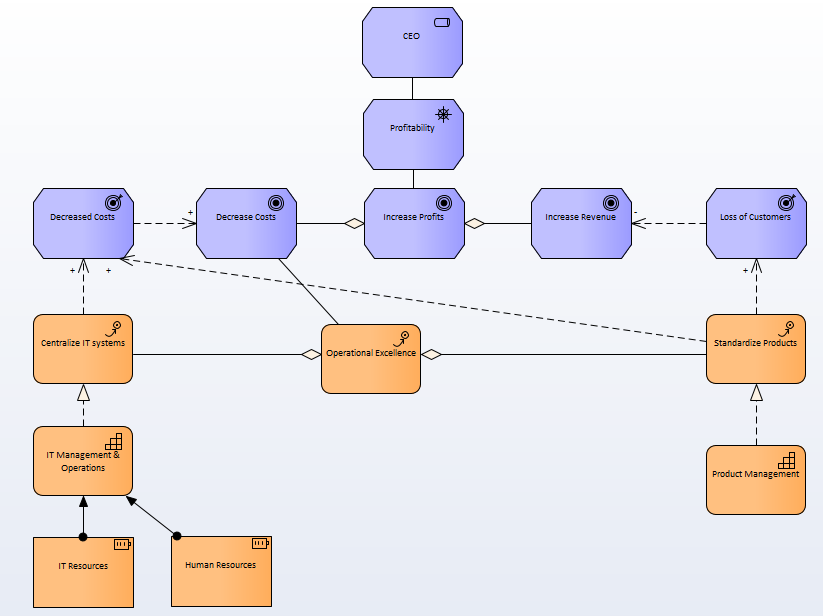
A great deal of IT Architects aren’t big fans of modeling languages, modell driven development and modeling tools. MS PowerPoint, Visio or other drawing tools are far too often used as a surrogate for a more structured approach. However communicating ideas clearly is crucial for an IT architect and not everything can be easily explained with words, and PowerPoint drawings are often too ambiguous in expression. Creating comprehensive diagrams and modells that clearly express the ideas is still crucial for IT Architects and developers to be able to communicate the ideas both in within the development teams. It is also crucial for efficient communication with other parties including the business stakeholders.
Photo: Shutterstock.com
For the Enterprise Architects over long time there was no good alternative to UML. UML is good for low level software modeling in particular application architecture. It is far less useful when communicating with business. There existed BPMN, but it was mainly covering process related modeling and not covering all the needs related to modeling strategy, tactics or even the business processes.
This was the situation until the arrival of ArchiMate in 2009. Based on IEEE 1471, developed by ABN AMRO and introduced by The Open Group The Open Group. Archimate defines three main layers: Business, Application, and Technology:
Business layer describes business processes, services, functions, and events. It describes the products and services offered to the external customers
Application layer describes application services and components
Technology layer describes hardware, communication infrastructure, and system software
Those three layers provide a structured way of bridging the different perspectives from business to technology and infrastructure.
However, the full model of ArchiMate 3.0 also brings or enhance another three very useful layers:
Strategy and Motivation layer – introduced in 2016 in ArchiMate 3.0 for modeling of the capabilities of an organization and help to explain the impact of changes on the business (gives a better connection between strategic and tactic planning)
Implementation and Migration layer – supports modeling related to project, portfolio or program management
Physical layer – for modeling physical assets like factories
These last three layers are crucial to properly bridge together the world of business with software and technology. In that sense, ArchiMate is bringing a new quality when it comes to modeling languages. ArchiMate 3.0 is also tightly connected and aligned with TOGAF 9.1 which makes it even more suitable as a new state of the art modeling language.
A simple example of Strategy and Motivation layer modeling
Summing up, ArchiMate 3.0 brings several new capabilities and qualities to modeling, which makes it a great tool for the digital age, where we are not only supposed to model the software and technology itself, but where it becomes increasingly important to be able to link the business models, strategy, tactics to the actual business processes and finally applications and technology.
There are few more traditional industries than power and utilities, and most likely nothing more common and little engaging than electrical power, so ubiquitous that we do not even notice its existence anymore. It is like air and water, it is just there.
Electrical power has been universally available since decades and while the tech heavy telco sector is struggling retaining their margins, fighting the inevitable commodity, dumb pipe fate and is gradually forced to find new revenues streams innovation, the traditional and commodity driven power sector is forced to innovate for completely different reasons. The result is probably the biggest technology shift since Nikola Tesla and Edisson invented the electric current. Once traditional and archaic, the power producers, TSOs and DSOs are slowly becoming the high tech champions as they implement Smart Grids, the electrical networks of the future.
The underlying reason is really a combination of different trends. There is of course general technology development, IoT, cheaper and more available sensors which provide data not so easily available til now. It is also much easier to transfer bigger amounts of data. The steadily increasing capacity of WDM fiber technology and availability of 4G coverage make it easy to send gigabytes of data practically from anywhere. NB-IoT technology on the other hand reduces the power consumption making it possible to deploy the battery driven sensors capable of sending data over multiple years. IP technology and convergence is also simplifying the traditional technology SCADA stacks, making the sensor data more easily accessible. With more affordable storage, memory, CPU power and technologies like Hadoop, Spark and in memory databases it is now possible to store petabytes of data and analyse it efficiently both with batch processing and streaming techniques.
Photo: NicoElNino/Shutterstock.com
On the other hand there is climate change and shift to renewable energy electric cars driven by rechargeable batteries or hydrogen a well as plugin hybrids demand more electric power and increase power consumption first of all in peak hours. Wind and solar power is also very difficult to control and the changes in supply have to be quickly compensated by other energy sources like gas turbines. New AMS (Advance Metering Services) power meters provide new possibilities when it comes to more dynamic pricing of energy. It is now possible to affect the consumer behavior by changing the price and moving some of the peak load to time of the day with lower demand for energy. With smart house technology it is also soon possible to control the consumption and cut off water heaters or car chargers instantly. Moreover with use of technology it is easy for the energy providers to predict the energy price changes and gain bigger market this way, which in turn puts the pressure on the TSOs and regulators to develop much more comprehensive and real time models to control the networks (e.g. ENTSO-E Common Grid Model)
The result is that the DSOs, TSOs and producers are simply forced to transition into high tech companies. Using IoT to collect new streams of data that can then be used to better predict the remaining lifetime of the assets or schedule the repair and maintenance more precisely. Using Big Data analytics to predict the faults before they occur and employing machine learning to analyse these huge quantities of data. All of this requires huge amounts of CPU power as well as flexibility and scalability thus pushing the energy sector into use of cloud, BigData (Spark and Hadoop) and other more traditional ways of handling and analysing huge amounts of data like OsiSoft PI. Moreover RDF stores and triple stores is another technology which is getting increasingly important for modeling the networks, analyzing, predicting and planning capacity allocation and managing congestions.
All of this is happening as we speak, take example of FINGRID and their newly completed ELVIS project, or look at the ENTSO-E Common Grid project, Statnett SAMBA project which aims optimizing the asset maintenance as well as AutoDIG which automates fault analysis and condition monitoring. Also Dutch Alliander is known for heavy and successful use of Advanced Analytics.
The last question still remains, is this just a short lasting phenomena or a long term trend and will these trends be enough to transform the power & utilities.
Although more and more western and in particular Scandinavian companies choose the digitalization and automation as the path to make their business more efficient and competitive, there are still quite a few of those that see offshoring as the best way to reduce their cost base and stay ahead of the competition. Collaboration pitfalls and barriers in offshoring projects are numerous. Here we explain a few of them based on observations made in multiple offshoring projects primarily between Scandinavia and South Asia.
Photo: Rafal Olechowski/Shutterstock.com
Differences in management models
The management models between the Scandinavian and asian cultures are very different. Scandinavian models are based mostly on consensus and put lots of emphasis on collaborative decision making. In Asia and in particular India the management model is very authoritative and hierarchical and the workers are normally not involved in decision making at all. The management models are inherently incompatible and are the root cause of many collaboration failures.
Work-life balance
In addition there are also several differences between Asian and Scandinavian workers when it comes to work-life balance. Asian workers tend to work much more, exceeding by far the number working hours usual for Scandinavian workers. This creates some pressure and tension in offshoring projects for instance as onshore Scandinavian workers would receive questions after working hours from their offshore peers and would feel stressed to respond straight away.
High turnover is also having certain effect on the work environment. Asian and in particular Indian workers are changing jobs every few months while in Scandinavia it is common to work several years or decades for the same company. In addition, Asian workers are expected to take care of their families and are often taking extended leaves due to family issues. Scandinavians on the other hand are often very loyal to their employer as well as they can rely more on the social welfare system for taking the care of their families.
High turnover and absence also affects collaboration in a negative direction as it makes it harder to create good relationships at work, reduce the trust, respect and it causes substantial overhead and waste due to frequent on-boarding and knowledge transfers.
Finally, the time difference between Scandinavia and South Asia is also a well-know factor, although it plays smaller role since the time difference is also limited (i.e. 4.5 hours between Norway and India). The offshore partners tend to internalize it and compensate by simply starting working later.
Tools and infrastructure
Efficient tools and infrastructure are often considered as a basic prerequisite, which we are not even conscious of anymore. Communication issues in offshoring projects are unfortunately still very common. In particular one could mention poor telephony and internet lines as well as poor videoconferencing facilities. These kind of issues make the collaboration very hard. Still there are many businesses that struggle with this kind of issues. In an offshoring project this becomes a top important prerequisite. The off-shore and on-shore teams are so dependent on the infrastructure that it simply has to work as efficiently as possible.
Transfer and search barriers
Morten T. Hansen in his book “Collaboration” defines several collaboration barriers, in particular search and transfer barriers. The search barriers are related to not being able to find what you look for in the organization while the transfer barriers are related to not being able to work with people you do not know well.
Transfer barriers in offshoring projects are mainly caused by knowledge transfer phase which is too short combined with very high resource turnover. Offshore workers are often simply unable to acquire enough knowledge and understanding of the subject matter in the short time that the knowledge transfer is allocated to, as well as the knowledge quickly evaporates as a consequence of high turnover. Search barriers on the other hand occur mostly due to insufficient understanding of the onshore organization. Here the turnover and knowledge transfer also plays an important role. Poor understanding of the organization leads to inefficient communication and delays in involving the right people at both ends.
Collocation
Collocation of the workers in the same office space can remedy some of the drawbacks related to the distance. However even in this case one may end up with different subcultures and groups. Although people are collocated and sit close to each other at the same location they still may tend to speak their native language instead of english. Instead of helping the communication the collocation the two groups will simply end up disturbing each other.
Lack of diversity
Scandinavian high tech workplaces are often very homogeneous and dominated by natives. It is also quite common with high expectations when it comes to use of native language although there are virtually no Scandinavian high tech workers who aren’t incredibly fluent in English. This may contribute to building a work environment which is little open for non-native speakers, does not acknowledge anything else and does not provide a good basis for efficient collaboration between offshore and onshore teams.
Cultural differences
At last also the culture is often a major obstacle to efficient collaboration. Cultural differences make it very hard to communicate due to differences e.g. in non-verbal communication. In particular the nodding for yes and no may be completely different in Indian culture than in Scandinavia. Another issue is related to “try and fail” approach which is relatively common way of finding solutions in South Asia. Scandinavians on the other hand take much more rational approach and require more evidence and data before even starting looking at a certain problem or task.
Moreover Scandinavians are simply more cautious and reserved when assessing and reporting the progress, while Asian contractors often may be tempted to provide better reports than the reality as they fear the consequences of negative reports from their own management.
Finally the offshore workers may show difficulties thinking independently enough and making the decisions on their own as they are constrained by their own hierarchy and management. In Scandinavia lack of independent thinking could be regarded as a insufficient competence and creativity which in turn contributes to reducing the trust and respect and again affects the collaboration negatively.
This were a few examples of reasons why collaboration in offshoring projects may be challenging and even fail. In our next article we will look into how to address these issues and improve them.
As functional programming paradigm becomes more and more broadly recognized,interest in functional languages (Scala, F#, Erlang, Elixir, Haskell, Clojure, Mathematica and many other) increases rapidly over last few years, it still remains far from the position that mainstream languages like Java and .NET have. Functional languages are predominantly declarative and based on principles of avoiding changing state and eliminating side effects. Several of these languages and frameworks like Scala/Akka and Erlang/OTP also provide new approach to handling the concurrency avoiding shared state and promoting messaging/events as a mean for communication and coordination between the processes. As a consequence they also provide frameworks based on actors and lightweight processes.
Fail-fast, on the other hand, as an important system design paradigm helps avoiding flawed processing in mission critical systems. Fail-fast makes it easier to find the root cause of the failure, but also requires that the system is built in a fault-tolerant way and is able to automatically recover from the failure.
Fail-fast combined with lightweight processes brings us to “Let it crash” paradigm. “Let it crash” takes fail-fast paradigm even further. The “Let it crash” system is not only build to detect and handle errors and exceptions early but also with an assumption that only the main flow of the processing is the one which really counts and the only one that should be implemented and handled. There is little purpose in programming in a defensive way, i.e. by attempting to identify all possible fault scenarios upfront. As a programmer, you now only need to focus on the most probable scenarios and the most likely exceptional flows. Any other hypothetical flows are not worth to spend time on and should lead to crash and recovery instead. “Let it crash” focuses on the functionality first and this way supports very well modern Lean Development and Agile Development paradigms.
As Joe Armstrong states in his Ph.D. thesis, if you canʼt do what you want to do, die and you should not program defensively, thus program offensively and “Let it crash“ Instead of trying focusing on covering all possible fault scenarios – just “Let it crash“
Photo: Pexels
However, recovery from a fault always takes some time (i.e. seconds or even minutes). Not all kinds of languages and systems are designed to handle this kind of behavior. In particular “Let it crash” is hard to achieve in C++ or Java. The recovery needs to be fast and unnoticed for the processes which are not directly involved in it. This is where functional languages and actor frameworks come into the picture. Languages like Scala/Akka or Erlang/OTP promote actor framework, making it possible to handle many thousands of processes on a single machine as opposed to hundreds of OS processes. Thousands of lightweight processes make it possible to isolate processing related to a single user of the system or a subscriber. It is thus cheaper to let the process crash, it recovers faster as well.
“Let it crash” is also naturally easier to implement in an untyped language (e.g. Erlang). The main reason for this is error handling and how hard it is to redesign the handling of exceptions once it is implemented. Typed languages can be quite constraining when combined with “Let it crash” paradigm. In particular, it is rather hard to change an unchecked exception into checked exception and vice versa once you designed your java class.
Finally “Let it crash” also implies that there exists a sufficient framework for recovery. In particular, Erlang and OTP (Open Telecommunications Platform) provides a concept of supervisor and various recovery scenarios of the recovery of whole process trees. This kind of framework makes implementing the “Let it crash” much simpler by providing a foolproof, out of the box recovery scheme for your system.
There are also other benefits of “Let it crash” approach. As there are now each end-user of your system, and each subscriber is represented as a single process, you can easily take into use advanced models like e.g. finite state machines. Even though not specific to Erlang or Scala, the finite state machines are quite useful to understand what has lead to the failure once your system fails. Finite state machines combined with a “Let it crash” frameworks can potentially be very efficient in for fault analysis and fault correction.
Although very powerful and sophisticated, “Let it crash” did unfortunately not yet gain much attention besides when combined with Scala/Akka and Erlang/OTP. The reasons are many, on one side (as explained above) the very specific and tough requirements on the programming languages and platforms but also the very fact that only the mission-critical systems really require this level of fault tolerance. In the case of classic, less critical business systems, the fault tolerance requirements are not significant enough to justify the use of a niche technology like Erlang or Scala/Akka.
“Perfect is the enemy of good” and mainstream languages like Java or .NET win the game again, even though they are inferior when it comes to fault-tolerance and supporting “Let it crash” approach.
Faced with the inevitable dumb pipe fate and commoditization of the telco business the last couple of years, several large telco operators started pursuing vertical and horizontal integration strategies. Horizontal, by expanding into other markets or consolidating. Vertical, by expanding either into downstream side of their value chain or into other verticals, in this way reinventing their business. On the other hand, many newcomers often don’t fear becoming a dumb pipe as much and take slightly different pathway by optimizing their cost base, challenging established operators and this way fighting for their market shares.
Photo: Pexels.com
France’s Iliad with their Free/Alice brands is currently the 2nd largest broadband operator and 3rd mobile operator in France challenging the old incumbent operator Orange (France Telecom). Both Iliad and Orange provide a wide range of bundled services to their customers (Triple/Quadruple Play) ranging from FTTH, VDSL, ADSL, landline and mobile telephony to TV. The other two major competitors like SFR and Bouygues also use similar bundling strategy to provide full Quadruple Play spectrum of services resulting in a lower total cost to their customers as well as increased ARPU for the operator.
Iliad’s network investment strategy has been initially focused on broadband Internet access services (ADSL and later FTTH) and their main revenues originate from Fiber/ADSL. Iliad however also provides other services primarily TV, VoD most of it bundled and free of additional charge to the subscribers. In 2012 strengthen Iliad further their market share by acquiring from a small ADSL operator from Telecom Italia – Alice and this year trying to acquire assets from CK Hutchinson and VimpelCom to become Italy’s fourth mobile operator.
The strategy that gave Iliad foothold in the telecommunication market was originally to use unbundled ADSL access from incumbent France Telecom. By doing that Iliad could achieve much higher margins than their competitors like Alice who did not have the same focus on unbundled ADSL and used much more expensive not unbundled ADSL access.
High prices and high margins on ADSL made it possible for Iliad to provide their bundled VoIP service practically for free (free local, long distance) as well as to provide hundreds free TV over ADSL channels. The only services that Iliad charged customers for in addition to ADSL were basically certain international calls, paid channels, VoD over ADSL as well as subscription VoD. Consecutively with their low cost structure Iliad was able to provide the most affordable basic ADSL-VoIP-TV bundle on the French market without compromising the performance of their ADSL. This combined with their comprehensive offer on the content side was basically what made Iliad so successful in tough French telco market.
Further when looking at Iliad’s fiber investments, by using sewers Iliad managed to bring the cost of fiber in Paris to a much lower level even comparable with ADSL. Iliad’s investment in FTTH is important for the future both to overcome the limitations of VDSL/ADSL as well as due to that the competitors have FTTH and FTTN/VDSL in their product portfolios. By doing FTTH investments at much lower cost than the competition and reusing the sewers Iliad gained a competitive advantage which neither Orange, SFR or Bouygues had. This is in a way an extension of their ADSL strategy where they also concentrated primarily on bringing the ADSL costs down and not just on achieving the economies of scope. Iliad has further used a similar strategy for expanding into the mobile market.
Summing up, by doing large infrastructure investments at lower costs than competition Iliad hopes to beat the competition on price/performance and gain larger market share. Lower cost and higher margins compared to the competition make it possible for them to bundle some basic VoIP and TV services at no additional charge. Iliad’s hope is that by doing this they can earn money later on advanced services.
Although very successful so far – Iliad’s low cost/dumb pipe strategy has also some weaknesses, e.g. lack of control over the content that might lead to their strategy falling apart in face of a strongly vertically integrated competitor. Without creating a compelling value proposition for the subscribers e.g. in form of an ecosystem and getting more control over the content Iliad is bound in long run to compete basically on price. The strategy of bundling more and more services at a lower price than the competition is a way of staying one step ahead of the competition. However it may not be sufficient without having more control over the content. On the other hand, there is a hope, since new technologies like IoT are expected to provide some new growth opportunities also for dumb pipe operators.
In our previous article we looked at different approaches to introducing Big Data technology in your business – either as a generic or specific solution deployed on premise or in cloud. Cloud gives obviously very good flexibility when it comes to experimenting in early stages when you need quick iterations of trying and failing before you find the use case and solution, which fits your business needs best.
Photo:Pexels
Cloud lock in
However in your try and fail iterations you will need to focus to not to fall in another pitfall – the cloud vendor lock-in or simply cloud lock-in. By cloud lock-in we mean using vendor specific implementations, which only a particular cloud supplier provides. A good example here could be Amazon Kinesis or Google Big Query. Using this specialized functionality may seem to be a quick way of implementing and delivering your business value however if your cloud provider chooses to phase out support for that functionality your business may be forced to reimplement parts or whole of the system that depends on it. A good strategy against lock-in is particularly important for established businesses although while for startups with relatively thin software stack this isn’t such a big deal since the switching costs are usually stil low.
Open source to the rescue
Open source software has a great track of providing a good solutions to reduce vendor lock-in. It has helped fighting vendor lock-in for decades. In particular within operating systems Linux has played an important role in fighting the vendor locking. Taking this into the Big Data world it does not take long time to understand that automation and in particular open source automation tools play important role in avoiding cloud lock-in. This could for instance be achieved by deploying and running the same complete Big Data stack on-premise and in the cloud.
Using automation tools, like Chef, Puppet, Ansible Tower is one of the strategies to avoid vendor locking and quickly move between the cloud providers. Also container technologies like Docker or OpenShift Containers make it possible to deploy the same Big Data stack, either it is Hortonworks, Coouder or MapR across different cloud providers, making it easier to swap or even use multiple cloud setups in parallel to diversify the operation risks.
What about Open Source lock-in?
Listening to Paul Cormier at RedHat Forum 2016 (Oslo) last week one quickly could get an impression that the cloud lock-in can simply be avoided by promoting Open Source tools like Ansible Tower or OpenShift Containers. These solutions effectively help turning the IaaS and PaaS resources offered by the Big Three (Amazon, Google and Microsoft) as well as other cloud providers into a commodity. On the other hand critics of Open Source could say that by using this kind of solution you actually get into another kind of lock-in. However the immense success of Open Source software over last 15 years shows that lock-in in case of an Open Source system is at most hypothetical. It is easy to find a similar alternative or in absolutely worst case scenario to maintain the software yourself. Open Source by its very nature of being open brings down any barriers for competitive advantage and the new ideas and features can easily be copied by anyone, anywhere and almost at no time.
As Big Data becomes more and more popular, and more and more options become available selecting Big Data technology for your business can become a real headache. Number of options of different stacks and tools is huge ranging from pure Hadoop and Hortonworks to more proprietary solutions from Microsoft, IBM or Google. If this wasn’t enough you will need to choose between on premise installation and cloud solution. Number of proprietary solutions also increases at a huge rate. Here we sum up a few strategies to introduce Big Data in your business.
One of the first questions you will meet when looking into possibilities of using Big Data for your business is if you should build a generic platform or a solution for specific needs.
Photo: Vasin Lee/Shutterstock.com
Building for specific needs
In many businesses, if you follow internal processes and project frameworks you will intuitively ask yourself what purpose or use case you want to support using Big Data technology. This approach may seem to be correct, but unfortunately, there is number of pitfalls here.
First of all, by only building a platform for specific needs and specific use cases, you will most likely choose a very limited product, which only mimics some of the features of a full-blown implementation. Examples here might be classical, old-fashioned analytical platforms like e.g. a Data Warehouse, statistical tools or even a plain old relational database. This will be sufficient for implementing your use case but as soon as you try to reuse it for another use case, you will realize the limitations. In particular the fact that you need to decide the structure of the stored data before you start collecting it, you need to transform it to adapt it to the new use case and face issues with scale-up every time the data volume increase and your Data Warehouse or relational database is unable to keep up with the volume and velocity of the data. You will in another word largely limit your flexibility and the possibility to explore your data.
A solution implemented for specific needs is in practice not really a Big Data solution although your vendor may insist calling it Big Data, thus this is just a Small Data solution. It may still be a viable choice for your business as long as you do not have any bigger ambitions or expectations in the future. By introducing more and more solutions like this you will ultimately fragment and disperse your business data into multiple loosely connected systems. The more fragmentation there is, the more difficult it gets to analyze data across your business.
Build a generic platform
Building a generic platform is much harder, but might be the right thing to do. It requires though courage to build a solution and start collecting data often without an adequate use case, to begin with. This is often difficult to advocate for, it is a leap of faith or a bet that your business needs to take. However, if you really want to unleash the power of Big Data, this is the strategy which potentially will both give you the flexibility to explore your data and to conduct experiments and find new facts, information and ways to use it for your business. This kind of platform based on open Big Data technology like Hadoop will also be easier to scale when needed and process increasing volumes and velocity of data.
The second very basic question one will meet is where to deploy and establish your platform – Cloud or on-premise? Although this question may seem really unrelated to it is important to be aware of the implications of chosen right deployment strategy.
On-premise platform
Choosing the on-premise platform seems like a natural choice here for many established business with established, in-house IT operations. However as soon as you choose to build a generic platform you will quickly realize that you need to experiment since the number of different Big Data stacks, technologies and tools is extreme. You need to be able to quickly change from one solution to another without too much lead time and waste. It may be hard to change the platform once you have heavily invested in an expensive proprietary on-premise platform like Oracle Big Data Appliance or even IBM Big Insights. It also requires people with a rather specific skill set to maintain the platform.
Cloud platform
Cloud-based Big Data platform like Amazon EMR, Google Cloud Platform or Microsoft Azure provides necessary flexibility and agility which is crucial when starting experimenting with Big Data. If you want to focus your business on what matters the most you will concentrate on the core of your business. Setting up hardware, installing Hadoop and running the basic Big Data infrastructure is not what most businesses need to focus on and should prioritize.
The cloud platform is especially relevant in the first, exploration phase when you are still unsure what to use the technology for. After the first exploration phase, when your solution is stabilized you may still reconsider sourcing in operations BigData technologies however in most of the cases you will like to still keep the flexibility of the cloud.
Summary
All in all, the best strategy is a platform which is open and flexible enough to cover future cases, do not build your BigData solution just for current needs. This is one of the cases when you actually need to concentrate more on technology and capabilities and not only the current, short-term business needs.
If you do not have time to dig into all possible variations of Big Data technologies, here is a quick (yet far from complete) overview over Big Data technologies, summarizing on-premise and cloud solutions.
Photo: is am are/Shutterstock.com
Main On-premise Big Data distributions
Hortonworks
Hortonworks established in 2011 and the only distribution that uses pure Apache Hadoop without any proprietary tools and components. Hortonworks is also the only pure Open Source project of all three distributions.
Cloudera
Cloudera was one of the first Hadoop distributions, established i 2008. Cloudera is based to large extent on Open Source components but not as much as Hortonworks. Cloudier is easier to installed use than Hortonworks. The most important difference from Hortonworks is the proprietary management stack.
MapR
MapR swaps HDFS file system with a proprietary MapRFS. MapRFS gives better robustness and redundancy and largely simplified use. Most likely the on-premise distribution that offers the best performance, redundancy and user friendliness. MapR offers extensive documentation, courses and other materials.
Comparison of most important Hadoop distributions (based on: “Hadoop buyers guide”)
Hortonworks
Cloudera
MapR
Data access
SQL
Hive
Impala
MapR-DB
Hive
Impala
Drill
SparkSQL
Data access
NoSQL
HBase
Accumulo
Phoenix
HBase
HBase
Data access
Scripting
Pig
Pig
Pig
Data access
Batch
MapReduce
Spark
Hive
MapReduce
Spark
Pig
MapReduce
Data access
Search
Solr
Solr
Solr
Data access
Graph/ML
GraphX
MLib
Mahout
Data access
RDBMS
Kudu
MySQL
Data access
File system access
Limited, not standard NFS
Limited, not standard NFS
HDFS, read/write NFS (Posix)
Data access
Authentication
Kerberos
Kerberos
Kerberos and native
Data access
Streaming
Storm
Spark
Storm Spark MapR-Streams
Ingestion
Ingestion
Sqoop
Flume
Kafka
Sqoop
Flume
Kafka
Sqoop
Flume
Operations
Scheduling
Oozie
Oozie
Operations
Data lifecycle
Falcon
Atlas
Cloudera Navigator
Operations
Resource management
YARN
YARN
Operations
Coordination
ZooKeeper
ZooKeeper
Sahara
Myriad
Security
Security
Sentry
RecordService
Sentry
Record Service
Perfromance
Data ingestion
Batch
Batch
Batch and streaming (write)
Perfromance
Metadata Architecture
Centralized
Centralized
Distributed
Redundancy
HA
Survives single fault
Survives single fault
Survives multiple faults (self healing)
Redundancy
MapReduce HA
Restart of jobs
Restart of jobs
Continuous without restart
Redundancy
Upgrades
With planned dowtnime
Rolling upgrades
Rolling upgrades
Redundancy
Replication
Data only
Data only
Data and metadata
Redundancy
Snapshots
Consistent for closed files
Consistent for closed files
Consistent for all files and tables
Redundancy
Disaster recovery
None
Scheduled file copy
Data mirroring
Management
Tools
Ambari
Cloudbreak
Cloudera Manager
MapR Control System
Management
Heat map, alarms
Supported
Supported
Supported
Management
ReST API
Supported
Supported
Supported
Management
Data and job placement
None
None
Yes
Other on-premise solutions
Oracle Cloudera
Oracle Cloudera is a joint solution from Oracle/Cloudera. Oracle based their Big Data platform on a Cloudera distribution. This distribution offers some additional and useful tools and solutions that give increased performance, in particular Oracle Big Data Appliance, Oracle Big Data Discovery, Oracle NoSQL database and Oracle R Enterprise.
Oracle Big Data appliance is an integrated HW and SW Big Data solution running on a platform based on Engineered Systems (like Exa Data). Oracle adds Big Data Discovery visualization tools on top of Cloudier/Hadoop while Oracle R Enterprise includes R – an open source, advanced statistical analysis tool.
IBM BigInsights
IBM BigInsights for Apache Hadoop is a solution from IBM that also builds on top of Hadoop. BigInsights offers in addition to Hadoop, some proprietary tool for analysis like BigSQL, BigSheets and BigInsights Data Scientist that includes BigR.
IBM BigInsights for Hadoop also offers BigInsights Enterprise Management solution and IBM Spectrum Scale-FPO file system as an alternative to HDFS.
Cloud solutions
Amazon EMR
Amazon EMR (Elastic Map Reduce) is a Hadoop distribution put together by Amazon and running in Amazon cloud. Amazon EMR is easier to take into use than on-premise Hadoop. Amazon is absolutely the biggest cloud provider but when it comes to BigData its solution is relatively new compared to Google.
Google Cloud Platform
Google offers also BigData cloud services. The most popular er known as BigQuery (SQL like database), Cloud Dataflow (processing framework) and Cloud Dataproc (Sparc and Hadoop services). Google has been working on BigData technologies since long which gives a good start point when it comes to advanced Big Data tools. GCP offers good analysis and visualization tools as well as an advanced platform test the solutions (Cloud Datalab).
Microsoft Azure
Microsoft offers three different cloud solutions based on Azure: HDInsights, HDP for Windows and Microsoft Analytics Platform System.
Comparison of most important Big Data cloud solutions
Amazon Web Services
Google Cloud Platform
Azure (HDInsights)
Data access
File system storage
Hadoop
Cloud Storage
Data access
NoSQL
HBase
Cloud Bigtable
HBase
Data access
SQL
Hive
Hue
Presto
BigQuery
Cloud SQL
Hive
Data access
RDBMS
Phoenix
Cloud SQL
Data access
Batch
Pig
Spark
Cloud Dataflow
Map Reduce
Pig
Spark
Data access
Streaming
Spark
Google Cloud Pub/Sub
Storm
Spark
Data access
Script
Pig
Data access
Search
Solr
Ingestion
Ingestion
Sqoop
Cloud Dataflow
Visualisation
Visualisation
CloudData lab
Analytics
Machine Learning
Mahout
Google Cloud Machine Learning Speech API Natural Language API Translate API Vision API
Preempting the EU Digital Single market regulations several Norwegian operators have introduced domestic rates for roaming in EU/EEA countries on selected subscriptions. Since majority of the Norwegian operators offer an AYCE (All you can eat) subscription with a data usage cap this means that the customers simply do not incur any extra charges while roaming in EEA countries.
Photo: Pexels
More than 4 months since this offer has been introduced we start seeing some interesting implications. In particular it is easy to see a few pitfalls when roaming in European countries and areas outside EU/EEA. Switzerland and the Vatican are probably the biggest surprises to many subscribers, confuse them and thus cause them to incur high charges.
While Telia Norway includes Switzerland in their new offer Telenor does not. The rates in those countries outside EEA are often very high. Norwegian subscribers have to be on guard when transiting these countries or in the border areas. The fear of high roaming costs is therefore still present to some extent. Telias move seems actually very smart because it is absolutely going to reduce the number of customer complaints due to incurred charges.
Data roaming throughputs in Spain
Data roaming throughputs in Poland
Our own tests conducted in a few EEA countries (including Poland and Spain) show also another interesting dilemma. Operators often use a list of preferred networks which are always selected first. This is done to reduce the costs for your home network operator. However, this does not mean that the customer will actually get the best quality of service (coverage and bit rate). Your phone may still select and roam into a 2G service or prioritize service offering 3G over a 4G. Moreover, it is common that roaming service is limited to 2G/3G. This has been observed in both countries where we conducted the test. We used Telenor subscription to conduct the tests so it is difficult to say if the same applies to Telia, however, this kind of preferred network list may easily become an interesting way of reducing costs for Telenor and Telia. This will be the case if the preferred network also happens to be the slowest one since it reduces the costs which roaming partners bill home network operator. Time will show if this will be the case if so there might be a need for advanced roaming benchmarks to compare the operators and help subscribers choosing the one that gives the best performance also while roaming.